반응형
ImageDataGenerator
모델링
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.models import Sequential
def build_model() :
model = Sequential()
# CNN
# input_shape은 이미지의 해상도가 다 다르기 때문에 고정시켜 줘야 한다.
model.add( Conv2D( filters = 16, kernel_size = (3, 3), activation='relu', input_shape = (300, 300, 3) ) ) # 첫 레이어는 input_shape이 들어가야 함
model.add( MaxPooling2D( pool_size = (2,2), strides = 2 ) ) # pool_size = 2행 2열 중 가장 큰 숫자로 다운사이징 하겠다. strides 는 2칸씩 이동하겠다.
model.add( Conv2D( filters = 32, kernel_size = (3, 3), activation='relu') )
model.add( MaxPooling2D( pool_size = (2,2), strides = 2 ) )
model.add( Conv2D( filters = 64, kernel_size = (3, 3), activation='relu') )
model.add( MaxPooling2D( pool_size = (2,2), strides = 2 ) )
# ANN
model.add( Flatten() )
model.add( Dense(units = 512, activation = 'relu') )
model.add( Dense(units = 1, activation = 'sigmoid') )
return model
model = build_model()
컴파일
from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=0.001),
metrics=['accuracy'])
Data Preprocessing
ImageDataGenerator를 이용해 학습
# model.fit()안에는 X_train과 y_train이 들어가야하는 데 numpy array가 들어가야 한다.
# 현재 우리는 png파일만 준비가 되어있다.
# 따라서 이미지파일을 넘파이로 바꿔주는 라이브러리를, 텐서플로우가 제공해준다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# ImageDataGenerator 사용법
# ImageDataGenerator라이브러리를 training용과 validation용 변수로 만든다.
# 파라미터는 (rescale = 1 / 255.0 이미지파일을 가져올때 이미지는 0부터 255까지니깐 255로 나눠서 가져와라 라는 뜻)
# 학습용
train_datagen = ImageDataGenerator( rescale = 1 / 255.0 )
# validation 용
validation_datagen = ImageDataGenerator( rescale = 1 / 255.0 )
# 변수로 만들어 줬으면, 그 다음 할 일은,
# 이미지가 들어있는 디렉토리의 정보, 이미지 사이즈의 정보, 분류할 갯수의 정보를 알려줘야 한다.
# target_size는 input_shape과 같아야 한다. 다만, input_shape은 컬러이기때문에 300,300,3이라고 기재했지만 target_size는 자동으로 컬러로 인식하기때문에 300,300까지만 기재하면 된다.
# class_mode = 기본적으로 Categorical로 되어있는데 이는 3개 이상 분류한다는 의미이다. 2개일땐 binary 이므로 데이터에 맞게 적용해 준다.
train_generator = train_datagen.flow_from_directory('/tmp/horse-or-human', target_size = (300,300), class_mode = 'binary' )
# 위의 train_generator는, numpy array와, 해당이미지의 정답지도 가지고 있는 변수이다.
# 즉, X_train과 y_train을 모두 한꺼번에 가지고 있다.
# validation data도 똑같이 만들어 준다.
# 즉, X_val과 y_val을 만들어 준다.
validation_generator = validation_datagen.flow_from_directory('/tmp/validation-horse-or-human', target_size = (300,300), class_mode = 'binary' )
# train_generator는 X_train과 y_train을 모두 한꺼번에 가지고 있기때문에 train_generator 하나만 써주면 된다.
# validation_generator 도 X_test, y_test를 모두 한꺼번에 가지고 있기 때문에 validation_generator 하나만 써주면 된다.
epoch_history = model.fit( train_generator, epochs = 20, validation_data = (validation_generator) )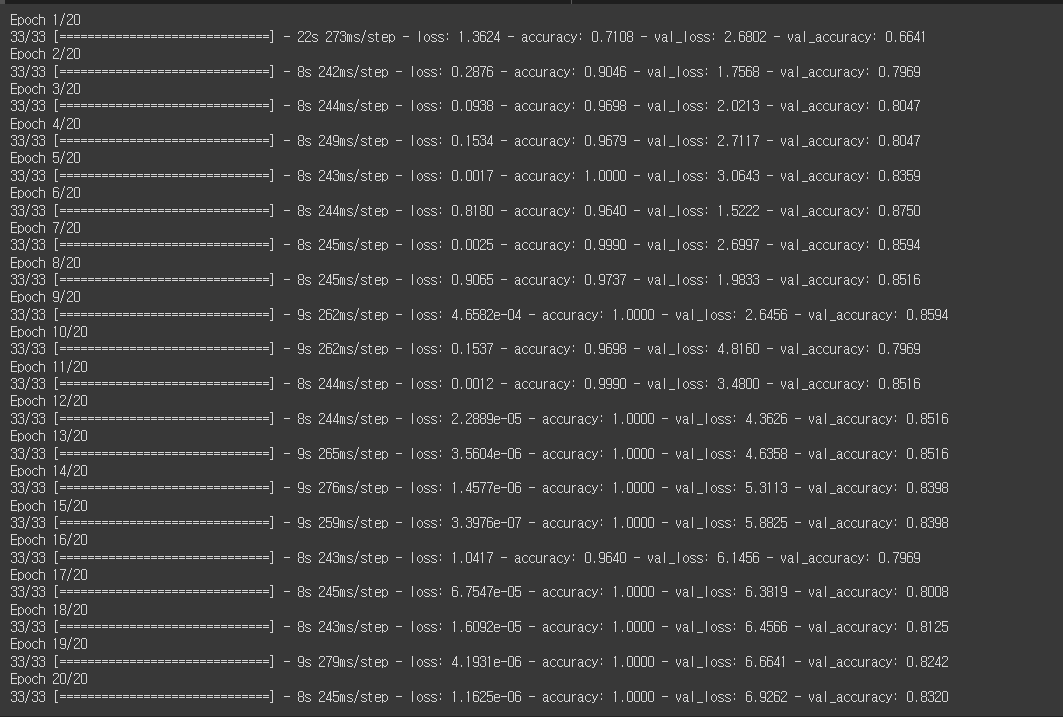
# 모델 평가
# 학습 정확도와 밸리데이션 정확도 차트로 그리기
model.evaluate(validation_generator)
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.legend(['train', 'validation'])
plt.show()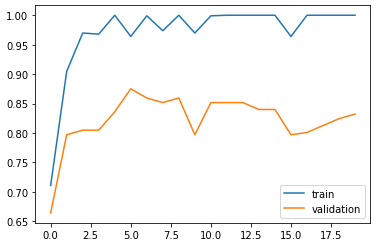
반응형
'Deep Learning > Tensorflow' 카테고리의 다른 글
| Tensorflow - os.mkdir 이용하여, 파일 저장할 다음 디렉토리 만들기 (0) | 2022.06.15 |
|---|---|
| Tensorflow - Colab에 file upload해서 모델에 적용하는 함수 (0) | 2022.06.15 |
| Tensorflow - Colab에서 인터넷에있는 파일을 다운로드 하는 방법 (0) | 2022.06.15 |
| Tensorflow - 파일을 다운받고 압축푸는 방법 (0) | 2022.06.15 |
| Tensorflow - CNN작업 전체 코드예시 (0) | 2022.06.14 |



