반응형
ITEM-BASED COLLABORATIVE FILTER
사용자의 평점을 이용하여
아이템 간의 유사도를 활용하는 추천 시스템이다.
추천 항목에 대한 사람들의 등급을 사용하여
계산 된 품목 간의 유사성
즉, 상관 관계( 상관계수 )를 기반으로하는
추천 필터링 시스템의 한 형태
영화 추천 예시를 통해
.corr() / .corrwith( )
활용에 대해 알아보자
영화 하나에 대한, ITEM-BASED COLLABORATIVE FILTERING 수행
movie_titles_df.shape
movies_rating_df.groupby('user_id')['user_id'].count()
movies_rating_df.corr()
movies_rating_df
피봇 테이블을 하여, 콜라보레이티브 필터링 포맷으로 변경
df = movies_rating_df.pivot_table(values= 'rating', index= 'user_id', columns='title', aggfunc='mean')
df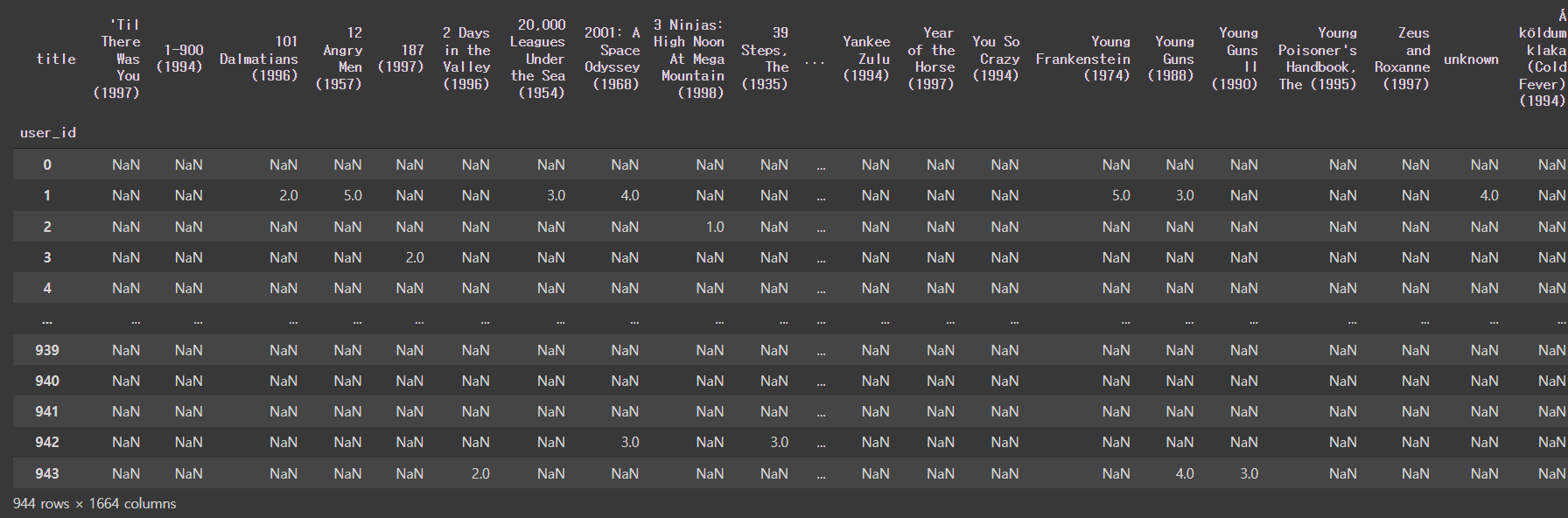
전체 영화와, 타이타닉 영화의 상관관계 분석을 하면,
타이타닉을 본 사람들에게 상관계수가 높은 영화를 추천하면 된다.
corrwith( ) 함수를 이용한다.
df['Titanic (1997)']
titanic_corr = df.corrwith( df['Titanic (1997)'] )
titanic_corr = titanic_corr.to_frame()titanic_corr.columns = ['correlation']titanic_corr
titanic_corr = titanic_corr.join( ratings_mean_count_df['count'] )
titanic_corr.dropna(inplace = True)
titanic_corr.sort_values('correlation', ascending=False)
titanic_corr.loc[ titanic_corr['count'] > 80 , ].sort_values('correlation', ascending=False)
변수.corr(min_periods= 80)
# min_periods= 80은 최소 80개이상 데이터가 있는것만 상관계수를 가져와라 라는뜻이므로
# min_periods= 파라미터를 사용해도 원하는 데이터를 가져올 수 있다.
반응형
'Machine Learning' 카테고리의 다른 글
| Machine Learning - error_bad_line & EDA & datetime64 & dt속성사용법 (0) | 2022.05.11 |
|---|---|
| Machine Learning - FaceBook Prophet Library (0) | 2022.05.11 |
| Machine Learning - WordCloud Visualizing (0) | 2022.05.11 |
| Machine Learning - CountVectorizer (analyzer) (0) | 2022.05.11 |
| Machine Learning - 구두점 & STOPWORDS(불용어) & Pipe Lining (0) | 2022.05.11 |



