반응형
Hierarchical Clustering
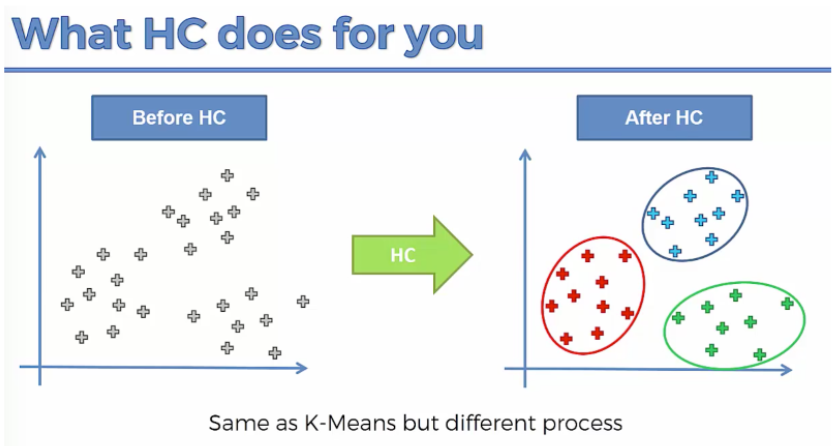

클러스터로 묶는 방법은?
거리를 측정해서 묶는다.



묶인 클러스터를 점 하나로 보고
반복하여 가까운것을 묶는다.

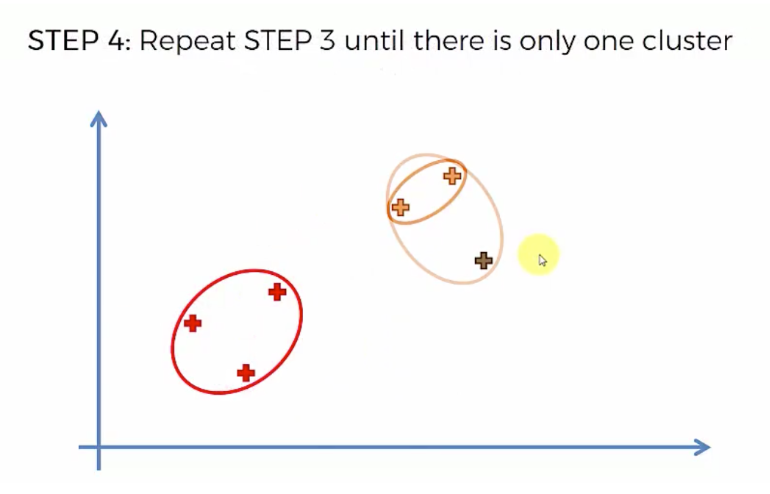
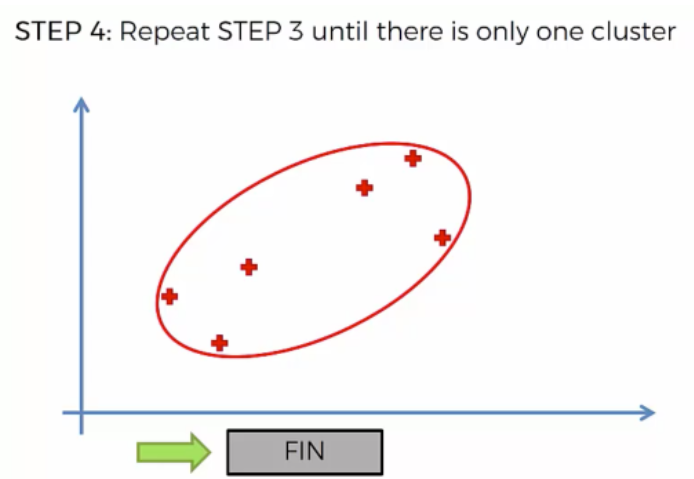
한 덩어리로 나올때 까지 클러스터링 한다

Dendrogram
덴드로그램은 개체 간의 계층적 관계를 보여주는 다이어그램이다.
가장 일반적으로 계층적 클러스터링의 출력으로 생성됩니다 .
덴드로그램의 주요 용도는
개체를 클러스터에 할당하는 가장 좋은 방법을 찾는 것이다.
아래 덴드로그램은 왼쪽에 표시된 6개 관측치 의 계층적 클러스터링을 보여준다 .
따라서 덴드로그램은 거리 행렬의 요약이다.

덴드로그램을 해석하는 핵심은 두 개체가 함께 결합되는 높이에 초점을 맞추는 것
위의 예에서 E와 F를 연결하는 링크의 높이가 가장 작기 때문에 가장 유사함을 알 수 있다.
다음으로 가장 유사한 두 개체는 A와 B이다.
클러스터에 관측치 할당
관측치는 덴드로그램에 수평선을 그려 클러스터에 할당된다.
아래 예시에는 두 개의 클러스터가 있습니다.
하나의 클러스터는 A와 B를 결합하고
두 번째 클러스터는 C, D, E, F를 결합합니다.

Dendrogram 출처 : https://www.displayr.com/what-is-dendrogram/
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
X = df.iloc[ : , 3 :]
Dendrogram을 그리고 최적의 클러스터 갯수를 찾아보자
import scipy.cluster.hierarchy as sch
plt.figure(figsize=[12,8])
sch.dendrogram(sch.linkage(X, method='ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Eculidean Distances')
plt.show()
Training the Hierarchical Cluster model
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters= 5 )
y_pred = hc.fit_predict(X)
df['Group'] = y_pred
df
그루핑 정보를 확인
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
반응형
'Machine Learning' 카테고리의 다른 글
| Machine Learning - GridSearchCV (0) | 2022.05.09 |
|---|---|
| Machine Learning - Word Cloud (Stopwords) (0) | 2022.05.09 |
| Machine Learning - K-Means Clustering (wcss & elbow method) (0) | 2022.05.09 |
| Machine Learning - Logistic Regression (이상한 값을 NaN으로 처리하기) (0) | 2022.05.08 |
| Machine Learning - KNN(K-Nearest Neighbor) (0) | 2022.05.08 |



