반응형
Word Cloud
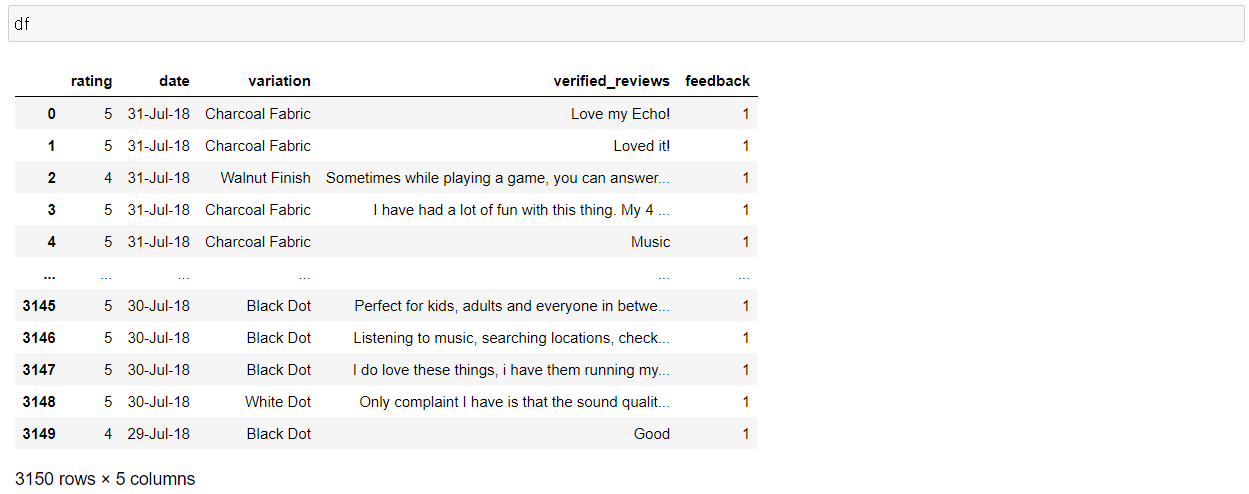
데이터셋은 아마존의 알렉사 제품에 대한, 3000개의 리뷰로 되어 있습니다.
컬럼은 rating, date, variation, verified_reviews, feedback
data set : www.kaggle.com/sid321axn/amazon-alexa-reviews
Word Cloud를 이용하여 유저들이
어떤 단어를 많이 사용 하였는지 시각화 해보자
프로젝트를 위해 아나콘다 프롬프트를 실행하고 다음을 인스톨하자
conda install -c conda-forge wordcloud
# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
1. 먼저, Word Cloud를 이용하기 위해
verified_reviews를 하나의 문자열로 만들어 보자
1 - 1 . verified_reviews를 하나의 리스트로 만든다.
review_list = df['verified_reviews'].to_list()
review_list
1 - 2 . 위의 Word List를 '' 공백으로 합쳐서, 하나의 문자열로 만든다.
reviews = ''.join(review_list)
reviews
2. Word Cloud를 이용하여 화면에 많이 나온 단어들을 시각화 한다.
from wordcloud import WordCloud, STOPWORDS
wc = WordCloud()2 - 1 . 불용어(STOPWORDS) 처리
필요 없는 단어를 불용어라고 한다.
필요 없는 단어는, 상황에 따라 다르므로, 각 상황에 따른 불용어를 처리한다.
my_stopwords = STOPWORDS
my_stopwords.add('Alexa')
my_stopwords
배경색이나, 불용어를 처리하도록 한다.
wc = WordCloud(background_color='white', stopwords= my_stopwords)
wc.generate(reviews)
plt.imshow(wc)
plt.axis('off')
plt.show()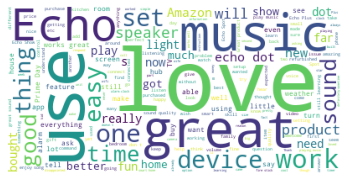
반응형
'Machine Learning' 카테고리의 다른 글
| Machine Learning - 구두점 & STOPWORDS(불용어) & Pipe Lining (0) | 2022.05.11 |
|---|---|
| Machine Learning - GridSearchCV (0) | 2022.05.09 |
| Machine Learning - Hierarchical Clustering (Dendrogram) (0) | 2022.05.09 |
| Machine Learning - K-Means Clustering (wcss & elbow method) (0) | 2022.05.09 |
| Machine Learning - Logistic Regression (이상한 값을 NaN으로 처리하기) (0) | 2022.05.08 |



